

Given that Bentley focuses a lot of its energy on civil infrastructure, an industry notoriously slow to adopt new solutions, it might be surprising to learn that the company’s solutions tend to keep up—easily—with the latest and greatest technological innovations. As I learned at this year’s Year in Infrastructure conference, its 3D capture solution ContextCapture is maintaining its position as one of the most feature-rich and technologically advanced on the market, to the point where the technology feels downright futuristic.
I caught up with Phil Christensen, SVP of reality modeling and cloud services, and Chintana Herrin, product marketing manager for reality modeling, for an overview of what’s new for ContextCapture in 2018.
Context Capture Insights: DIY machine learning
Bentley is currently offering an early access program for a new reality modeling solution called ContextCapture Insights, which “automatically detects and locates objects using 3D-machine learning technologies.” Christensen calls the solution a “machine learning training environment,” and describes the workflow like this:
Let’s say you want ContextCapture to recognize all of a certain type of valve. Open up your photo set, and ContextCapture will visualize the model and the photos side by side, making it easy to navigate—pick a spot in the model or the photos and the software will snap to the right place in the other data set. Use this functionality to find your valves, and then put bounding boxes around them. “You only do it in a hundred photos or so,” says Christensen, “and that’s enough to train the algorithm.” Next, you feed the solution the data set, and it finds the objects in all the other photos.
Here’s where it gets interesting. “We know where these photos are, and which way they’re pointing,” he told me. “So that means when we find the same object in the model as the photos, we can project a spatial bounding box of the thing that’s been identified.”
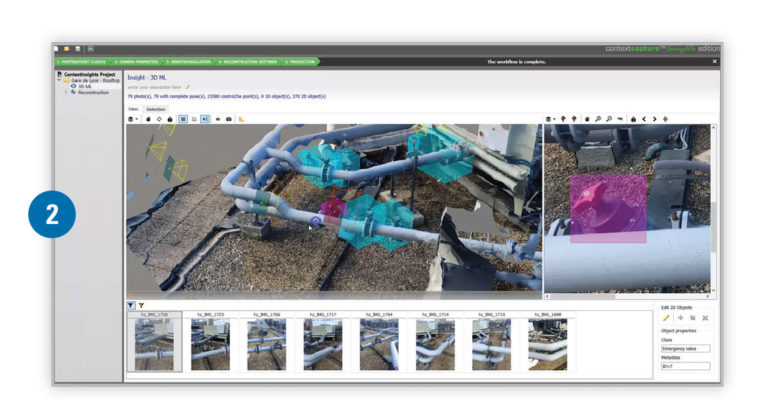
Step 2: Bounding boxes in 3D space.
Now that ContextCapture knows where each of these valves exists in 3D space, the software can “shrink wrap that spatial bounding box onto the reality mesh—so then we get the actual object you’ve found. It’s just the part of the mesh that’s the object in question.”
To finish off your workflow, you can export all the information that you just taught the system, and then bring it into other applications. For instance, set it up automatically link to your asset management system with no human intervention.
This workflow is slightly more momentous than it seems. Though machine-learning is commonly used across a wide variety of industries, Christensen notes that the data sets Bentley customers deal with are much different than other industries. You could easily find a machine learning algorithm that was trained to recognize cats, cars, faces, defects, and so on, but it was virtually impossible to come by machine-learning algorithms that had been trained to recognize valves, and beams, and other built-world specific objects. And Christensen tells me to expect more of the same soon.
With ContextCapture Insights, you can just train one yourself—pretty quickly, too—and get on with it. For those interested, Bentley is offering an early access program for the solution. Find out more here.
Analytics at a glance/resolution maps
Next, we dug into into Bentley’s hybrid modeling functionality, which allows users to seamlessly blend lidar point clouds and photogrammetric meshes into a single 3D mesh data set. Christensen says Bentley is seeing more of these combination data sets that combine “the accuracy of the point cloud and the visual fidelity of the photos.”
To enhance this functionality, ContextCapture now features analytical services that can show you, at a glance, how accurate your model is. Herrin showed me how the quality report has been updated to colorize the data for a quick understanding of quality. The first visualization below, for instance, shows the resolution of the data. The second shows a top view of the scene indicating how many photos “see” each part of the scene.
The new Resolution Map offers an even more granular way to see the quality of your data. “Here’s our campus, modeled with about 100 hundred photos taken with a drone,” Herrin says as she pulls up a video (see below). “Now, I’ll switch over, and you can see it varies from red to green—red being the lowest resolution, green the highest, and the yellow in the middle. That’s from 150 photos. Now, we’ll up it to 500, and you can see a lot more green.”
Auto alignment with no ground control / optimization for thin structures
Next, Herrin demonstrated a new alignment workflow. Traditionally, she says, you would align point clouds and photos using ground-control points. ContextCapture has been updated to perform aerotriangulation and alignment automatically, which means this stage of the workflow is faster, as well as improve its accuracy.
A related update: Bentley has optimized ContextCapture’s aerotriangulation processing to better handle thin structures, like telecommunications towers.
A confluence of technologies
Throughout our talk, Christensen often referred to the wide variety of technologies that make all of this possible. He called the ContextCapture Insights solution, for instance, the “convergence of cloud-based web viewing, machine learning, GPU processing, and different types of data capture—all coming together to solve a problem. That’s pretty cool.”
For more information, including availability and pricing, see Bentley’s website and contact the company directly.



